The Next Frontier in AI: Full Duplex Modeling and the Future of Conversational AI
A recent paper, “Language Model Can Listen While Speaking,” published in August 2024 by researchers from Shanghai Jiao Tong University and ByteDance Inc, recalls the early days of Generative Adversarial Networks, or GANs, introduced in 2014 via Ian Goodfellow’s pivotal work, “Generative Adversarial Networks.” GANs, which generate new data like images or audio, proved transformative a decade ago. Now, full duplex language models, where AI listens and speaks simultaneously, signal a comparable shift. This technology holds potential to redefine human-AI interaction.
Advances like GANs opened doors to creating everything from lifelike visuals to synthesized audio. Full duplex modeling promises a similar leap for conversational AI, enabling smoother, more responsive exchanges between humans and machines.
What Is Full Duplex Modeling?
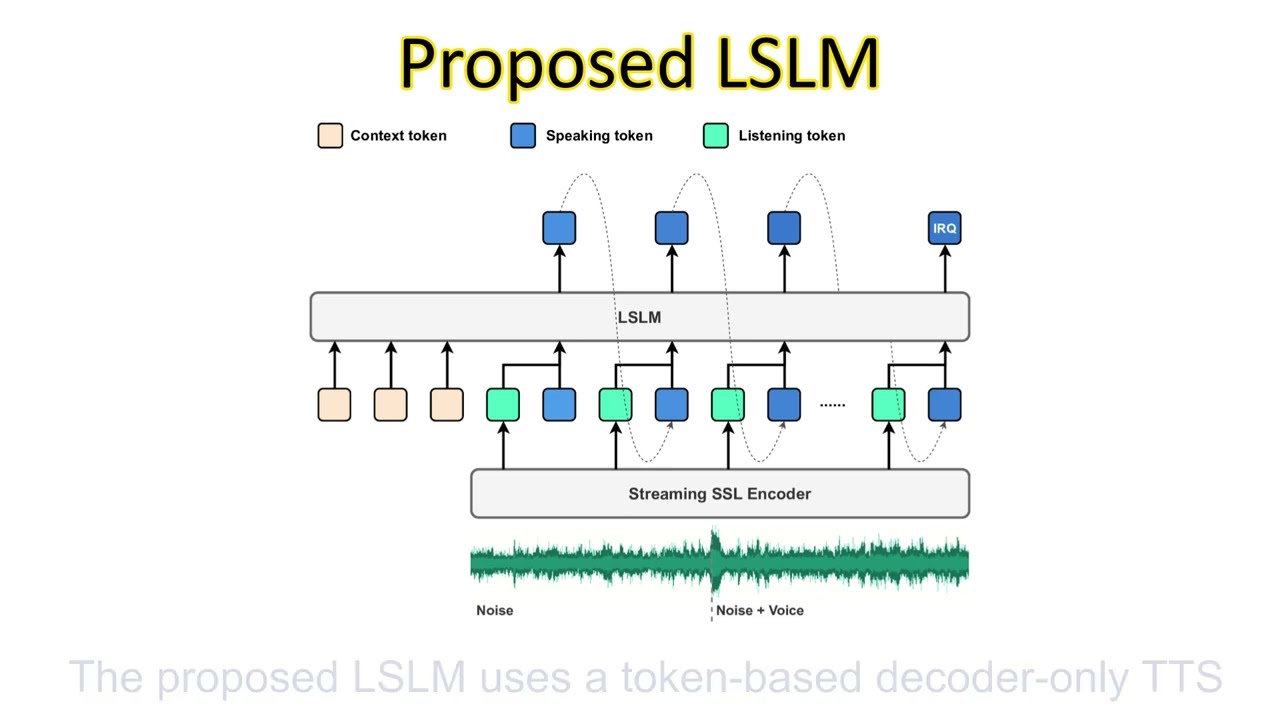
Current conversational AI operates like a walkie-talkie: you speak, it listens; it speaks, you wait. The system is rigid. Interruptions often force a restart. The Listening-while-Speaking Language Model (LSLM), detailed in this paper, changes that. It pairs a speaking channel, powered by token-based text-to-speech, with a listening channel, driven by a streaming self-supervised encoder. These work together, allowing the AI to detect and respond to interruptions in real time. The demonstration is rough but compelling:
Tested with noise and diverse voices, it shows resilience. This isn’t a finished product, but its path forward is clear.
How LSLM Works
A diagram outlining the simultaneous processing of speaking and listening in LSLM. Click to enlarge.
A Transformative Parallel: From GANs to Full Duplex
In 2014, Goodfellow and his team laid the groundwork for GANs, a milestone that became central to modern AI. Its impact was sweeping, enabling machines to craft data with stunning realism, like generating lifelike faces or turning sketches into photorealistic scenes. That early work fueled the massive wave of AI innovation we see today. Companies like xAI use GANs to enhance tools like Grok, creating richer training data for sharper responses. Modern image generation systems use related generative principles to create visual outputs from text prompts, while other AI labs apply the same family of techniques to photo enhancement, simulation, and synthetic training data. It’s simple: one network generates fakes, another critiques them. Over time, they get so good the fakes look real.
Full duplex modeling follows a similar arc. It’s early, open-source (demo available here), and brimming with promise, much like GANs in their youth. Where GANs mastered creation, this technology excels at interaction: fluid conversations with interruptions handled smoothly. The next advance is in sight: multilingual capability. An AI that listens and speaks across languages in real time is close. Here at Sprinklenet, we’re probing this edge with our real-time language analysis research, using vector database embedding models to process language on the fly. Full duplex could supercharge that, delivering smooth, multilingual exchanges effortlessly.
The Stakes: China’s Pace and America’s Response
This research hails from Chinese institutions and ByteDance, the force behind TikTok. That matters: China is pushing AI hard and fast. This paper is a wake-up call. American innovation has shaped the tech world, but holding that lead demands bold investment and quick moves. We need to be the ones driving this.
Take call centers and business process outsourcing: they’ll see instant gains. Today’s systems falter when interrupted, dropping context and slowing responses. Full duplex AI shifts on the spot. A customer cuts in, and it adjusts without skipping a beat, improving service and cutting costs. But it’s bigger than that. Voice-to-text apps, navigation systems, even virtual assistants will turn more fluid, more human-like. Picture getting directions where you can ask questions mid-flow, or an AI tutor that adapts as you speak your thoughts. This could even edge us closer to an immersive, adaptive experience, think artificial general intelligence (AGI), where AI mirrors our stream-of-consciousness, responding in real time with uncanny depth.
Seizing the Moment
This technology is young. Much work remains. We need to explore and test what’s out there and what’s in development before we can pin down timelines for integration, usability, and reliability. But it’s coming, no question, and it will upend every business and consumer application we know.
We’re skilled at deploying sophisticated AI-powered chatbots, integrated with business data and customized AI RAG systems, as part of our broader artificial intelligence services. We excel at weaving existing IT systems into intelligent overlays, delivering real value now, as we outlined recently on LinkedIn. Still, the next wave, fueled by this voice and audio fusion, will be smooth beyond anything we’ve seen. We see this as a chance to push AI forward, keeping the U.S. at the cutting edge. If you’re interested in exploring this future, reach out on X (@Jamie_Thompson), LinkedIn, or via email.
For more on how Sprinklenet is pushing AI forward today, check our recent LinkedIn article below. Together, we can shape the future of AI.
References: